本文仅为科普、纠错、说明,并非研究性/新技术的讲解
如有理论错误,欢迎联系修改。
本文中所有资料均可被自由引用。
最终解释权归 錾制千秋yuno779 所有。
推荐阅读文档和视频:Finetune&LoRA&LyCORIS
潜工具书:Stable Diffusion 潜工具书(中文最全文档)
1. 融合模型是不是都是垃圾?
首先可以明确的说:融合模型并不都是垃圾,只是有些人融合出的模型,确实垃圾。
首先,融合模型是相当简单直接的一个事,你只需要webui整合包然后动动手指点点鼠标就可以了,搞的人多了自然而然的垃圾就多。现在无论是哪个平台绝大部分模型都是融合的,所有很多人对于融合模型是什么感知并不是很明显。具体自行尝试就可以了,以及还有一个插件叫“SuperMerge”也是很好用的。
有问题的是有一部分人将一个现有的模型融了0.05的其他模型这种“冰红茶滴尿”的行为,这种有的时候因为原模型质量好且只融了0.05,模型其实也不差,但是我们依旧会称这个模型是垃圾模型。
还有一部分人,将一些练的比较差的LoRA融到模型里,导致了模型出图烂,有些时候会出现细节爆炸的情况。这些模型使用还是用于训练,都是很痛苦的。
见得多了就会有刻板印象认为融了LoRA的模型都是垃圾,但并不是说融了LoRA的模型质量都很差。使用LoRA/LyCORIS去炼底模是相当常见的,Kohaku V3/4/5、Kohaku XLdelta、SDAS A3.33等这些模型都是用这样搞得。
另外,绝大部分模型的融合配方其实都保存在了模型里,一查便知这融了什么模型。当然有些操作可以将其删除或者更改,不过除了metadata这种直接的方式查看模型的成分之外,还有其他方法可以找到这个模型的融合配方,麻烦一点而已。
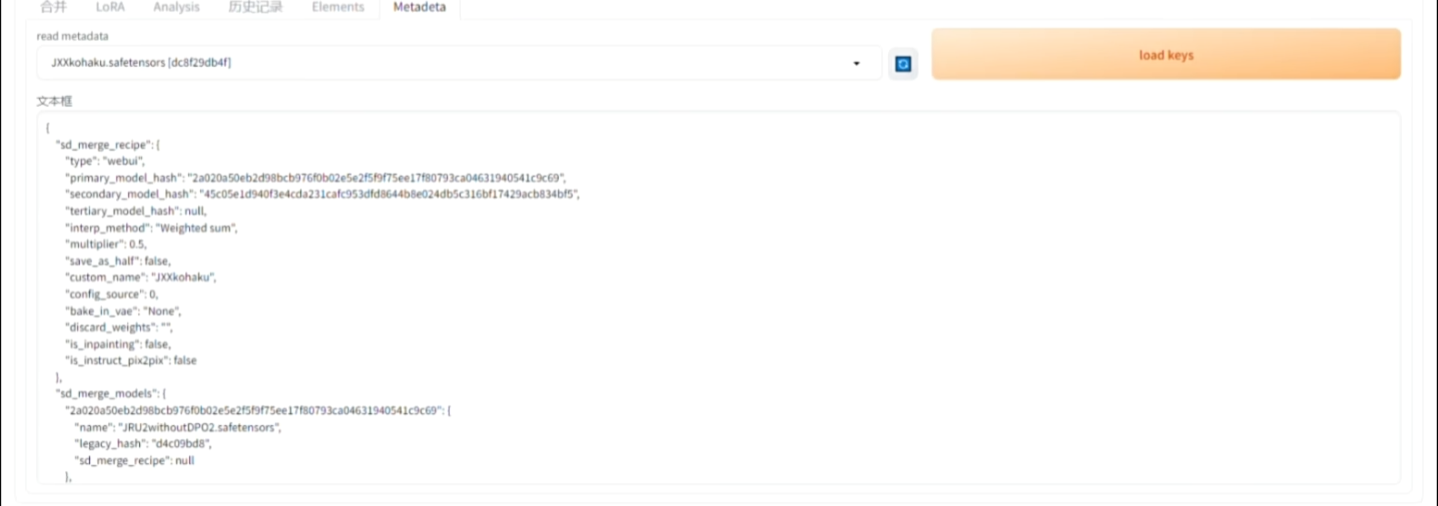
下面是GhostXL的模型融合元数据:
{
“sd_merge_models”: {
“3fe89f167db02dfba3616042e948767dcc61088373f81460fe44c8609d3a90cd”: {
“name”: “SDXL_train_ghost_test2”,
“legacy_hash”: “f61799f2”
},
“d8fd60692a589f3be4a4c205ae4fa5a1d686b44a1cc20c7953715a95ab5070cf”: {
“name”: “SDXL_LEOSAM HelloWorld u65b0u4e16u754c _ SDXLu771fu5b9eu611fu5927u6a21u578b_v5.0”,
“legacy_hash”: “e1c7ea87”
},
“4726d3bab1876f5c23734c871c47901fde305115e15fbfa3f33354ac45b11c67”: {
“name”: “SDXL_dreamshaperXL_v2TurboDpmppSDE”,
“legacy_hash”: “488f085e”
}
},
“format”: “pt”,
“sd_merge_recipe”: {
“type”: “sd-webui-supermerger”,
“weights_alpha”: null,
“weights_beta”: null,
“weights_alpha_orig”: null,
“weights_beta_orig”: null,
“model_a”: “3fe89f167db02dfba3616042e948767dcc61088373f81460fe44c8609d3a90cd”,
“model_b”: “d8fd60692a589f3be4a4c205ae4fa5a1d686b44a1cc20c7953715a95ab5070cf”,
“model_c”: “4726d3bab1876f5c23734c871c47901fde305115e15fbfa3f33354ac45b11c67”,
“base_alpha”: 0.15,
“base_beta”: 0.15,
“mode”: “Triple sum”,
“mbw”: false,
“elemental_merge”: “”,
“calcmode”: “normal”,
“Off”: [
“”
]
}
}
不要总是标榜自己是什么模型大师什么名校毕业,然后随便融合出来一个模型说这是我自己做的新的模型,并且还不标注融合配方,或者标榜自己的模型有多高的热度,多么的nb。
融合模型其实是非常棒的,你可以循序渐进的调整出自己想要的东西,不管是画风还是人物,但是请你再介绍自己融合的模型的时候,留下原模型的名字或作者来表示对他人的尊重。
2. LoRA适配性越高模型质量越好?
● 模型训练在数学上是怎么讲解的
一个很简单的模型:(看不懂回去读高中)
F(X)=WX+B
从F(X)为基础训练一个g(X)=W’X+B,只改变上面的W,W→W’这个过程就是微调
● 而LoRA/LyCORIS可以这样解释
同样是考虑W→W’,我们可以将其看成g(X)=WX+B+(W’-W)X,也就是g(X)=F(X)+(W’-W)X,相当于说微调就是在F(X)的基础上,额外加上一个h(X)=△W(X),其中△W=(W’-W)
如果你的模型很大,这就意味着你的h(X)也很大,代表你需要使用更多的资源去微调你的模型,代表你的显卡可能装不下,最开始炼制SDXL使用3090/4090的24G都可以吃满,这个时候我们就不想要花这么大的力气去处理h(X),模型很大那么△W自然也会很大,因为矩阵是相同形状的,但是实际上很多时候我们并不需要这么大的△W。
而LoRA(提供精简版的△W),LyCORIS(各种不同的方式去模拟一个△W),就是用更少的参数量去产生一个h(X)。(也就是PEFT)。本质上LoRA和LyCORIS就是微调,他们做的事情是一样的。在这个前提下,自然就没有“CKPT模型是画板,LoRA是画笔”这个说法
● LoRA通用性越高越好?(错误)
而LoRA适配性是只有在“模型都有同一个爹”(模型本身差别小)的基础上才会去讨论的。
因为LoRA/LyCORIS的使用可以看作:
g(X)=WX+B+(W’-W)X
而这个W就是原本的模型。当这个W改变时(变成N),那么我所达到的效果就会变成这样:
g'(X)=NX+B+(W’-W)X
这个时候我们还想达到原来完全相同的效果就成了:
g(X)=WX+B+(W’-W)X+(W-N)X
这样这两个我们如果混用LoRA,那么始终就有有一个(W-N)X的差别
g(X)-g'(X)=(W-N)X
如果模型本身差别都很小(比如模型都有同一个爹),那么(W-N)X这一点差别是可以忽略不计的;如果模型本身差距足够大(例如:SDXL的二次元不同派系模型大都是从SDXL1.0基底直接训练的;SD1.5的ink_base和novelAi这些不同的从SD1.5本体直接练的模型),那么这个(W-N)X足够大,混用LoRA就会造成生成图扭曲甚至崩图的情况。
总结下来就是LoRA的适配性(通用性)和模型的质量毫无任何关系
那么我们有的时候需要使用别人已经训练好的LoRA的时候应该怎么办呢?
首先如果你使用的是非常常见的CHECKPOINT模型我们可以直接拿对应模型的LoRA,一些人训练的时候会区分不同的版本。
那如果并不是使用的常见的CHECKPOINT模型,那我们就要给这个模型溯源找近亲。比如你使用的CHECKPOINT模型是从KohakuXL上训练来的,那么这个时候(W-N)X足够小,混用LoRA对于本身的影响并不是很大,这个时候就混用影响并不是很大。
当然二次元方面你也可以使用SD1.5的模型,SD1.5的二次元模型大致上只有Nai一个派系。这些模型的LoRA大都可以混用,因为这些模型都有一个共同的爹(NovelAI V1)
当然了,有一部分人在SD1.5时期玩的多了,就根据片面的现象草草的认为LoRA泛用性跟模型质量有关。这其实是错误的,模型可以泛用其实是“附加题”,跟模型本身质量是没关系的。
3. 模型越大越好?(junkdata!)
老生常谈的问题,看下面秋叶的文章就知道了。当然了,下面举例不想看直接左侧目录跳转下一部分就行了。
【AI绘画】模型修剪教程:8G模型顶级精细?全是垃圾!嘲笑他人命运,尊重他人命运 – 哔哩哔哩 (bilibili.com)
这里举个例子,我把这个模型拆开后直接拿出了没用的键值:
None-Bayonetta:
embedding_manager.embedder.transformer.text_model.encoder.layers.0.layer_norm2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.0.layer_norm2.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.0.mlp.fc1.bias [3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.0.mlp.fc1.weight [3072,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.0.mlp.fc2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.0.mlp.fc2.weight [768,3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.0.self_attn.k_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.0.self_attn.k_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.0.self_attn.out_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.0.self_attn.out_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.0.self_attn.q_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.0.self_attn.q_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.0.self_attn.v_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.0.self_attn.v_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.layer_norm1.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.layer_norm1.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.layer_norm2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.layer_norm2.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.mlp.fc1.bias [3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.mlp.fc1.weight [3072,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.mlp.fc2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.mlp.fc2.weight [768,3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.self_attn.k_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.self_attn.k_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.self_attn.out_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.self_attn.out_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.self_attn.q_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.self_attn.q_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.self_attn.v_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.1.self_attn.v_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.layer_norm1.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.layer_norm1.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.layer_norm2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.layer_norm2.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.mlp.fc1.bias [3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.mlp.fc1.weight [3072,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.mlp.fc2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.mlp.fc2.weight [768,3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.self_attn.k_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.self_attn.k_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.self_attn.out_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.self_attn.out_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.self_attn.q_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.self_attn.q_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.self_attn.v_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.10.self_attn.v_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.layer_norm1.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.layer_norm1.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.layer_norm2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.layer_norm2.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.mlp.fc1.bias [3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.mlp.fc1.weight [3072,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.mlp.fc2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.mlp.fc2.weight [768,3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.self_attn.k_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.self_attn.k_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.self_attn.out_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.self_attn.out_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.self_attn.q_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.self_attn.q_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.self_attn.v_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.11.self_attn.v_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.layer_norm1.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.layer_norm1.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.layer_norm2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.layer_norm2.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.mlp.fc1.bias [3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.mlp.fc1.weight [3072,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.mlp.fc2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.mlp.fc2.weight [768,3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.self_attn.k_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.self_attn.k_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.self_attn.out_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.self_attn.out_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.self_attn.q_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.self_attn.q_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.self_attn.v_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.2.self_attn.v_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.layer_norm1.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.layer_norm1.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.layer_norm2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.layer_norm2.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.mlp.fc1.bias [3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.mlp.fc1.weight [3072,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.mlp.fc2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.mlp.fc2.weight [768,3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.self_attn.k_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.self_attn.k_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.self_attn.out_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.self_attn.out_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.self_attn.q_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.self_attn.q_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.self_attn.v_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.3.self_attn.v_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.layer_norm1.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.layer_norm1.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.layer_norm2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.layer_norm2.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.mlp.fc1.bias [3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.mlp.fc1.weight [3072,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.mlp.fc2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.mlp.fc2.weight [768,3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.self_attn.k_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.self_attn.k_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.self_attn.out_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.self_attn.out_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.self_attn.q_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.self_attn.q_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.self_attn.v_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.4.self_attn.v_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.layer_norm1.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.layer_norm1.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.layer_norm2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.layer_norm2.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.mlp.fc1.bias [3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.mlp.fc1.weight [3072,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.mlp.fc2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.mlp.fc2.weight [768,3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.self_attn.k_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.self_attn.k_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.self_attn.out_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.self_attn.out_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.self_attn.q_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.self_attn.q_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.self_attn.v_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.5.self_attn.v_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.layer_norm1.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.layer_norm1.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.layer_norm2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.layer_norm2.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.mlp.fc1.bias [3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.mlp.fc1.weight [3072,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.mlp.fc2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.mlp.fc2.weight [768,3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.self_attn.k_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.self_attn.k_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.self_attn.out_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.self_attn.out_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.self_attn.q_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.self_attn.q_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.self_attn.v_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.6.self_attn.v_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.layer_norm1.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.layer_norm1.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.layer_norm2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.layer_norm2.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.mlp.fc1.bias [3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.mlp.fc1.weight [3072,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.mlp.fc2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.mlp.fc2.weight [768,3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.self_attn.k_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.self_attn.k_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.self_attn.out_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.self_attn.out_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.self_attn.q_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.self_attn.q_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.self_attn.v_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.7.self_attn.v_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.layer_norm1.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.layer_norm1.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.layer_norm2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.layer_norm2.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.mlp.fc1.bias [3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.mlp.fc1.weight [3072,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.mlp.fc2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.mlp.fc2.weight [768,3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.self_attn.k_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.self_attn.k_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.self_attn.out_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.self_attn.out_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.self_attn.q_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.self_attn.q_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.self_attn.v_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.8.self_attn.v_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.layer_norm1.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.layer_norm1.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.layer_norm2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.layer_norm2.weight [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.mlp.fc1.bias [3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.mlp.fc1.weight [3072,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.mlp.fc2.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.mlp.fc2.weight [768,3072]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.self_attn.k_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.self_attn.k_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.self_attn.out_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.self_attn.out_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.self_attn.q_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.self_attn.q_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.self_attn.v_proj.bias [768]
embedding_manager.embedder.transformer.text_model.encoder.layers.9.self_attn.v_proj.weight [768,768]
embedding_manager.embedder.transformer.text_model.final_layer_norm.bias [768]
embedding_manager.embedder.transformer.text_model.final_layer_norm.weight [768]
4. 模型prompt写法是不同的
总有人在使用SDXL模型的时候继续沿用SD1.5的习惯格式而不用模型卡的推荐设置,这会导致出图达不到预期。当然出图达不到预期这只是现象,这实际上只是模型作者在训练的时候使用的标注格式不同,。
比如kohakuXL就是使用的如下:
1girl,
klee, genshin impact,
XXXXX,
cabbie hat, twintails, coat, watermark, sidelocks, sparkle background, red coat, long hair, bag, hair between eyes, backpack, pointy ears, pocket, clover, hat, holding, sparkle, chibi, red headwear, low twintails, brown gloves, sparkling eyes, gloves, simple background, light brown hair, hat feather, four-leaf clover, artist name, ahoge, feathers, solo, sparkling aura, hat ornament, orange eyes, food in mouth, clover print, white feathers, long sleeves, +_+,
masterpiece, newest, absurdres, safe
那么我在使用其他的tag格式的时候,出图就很难达到预期(有些效果出不来,有些效果乱出)。
下面是另外两个模型的tag格式。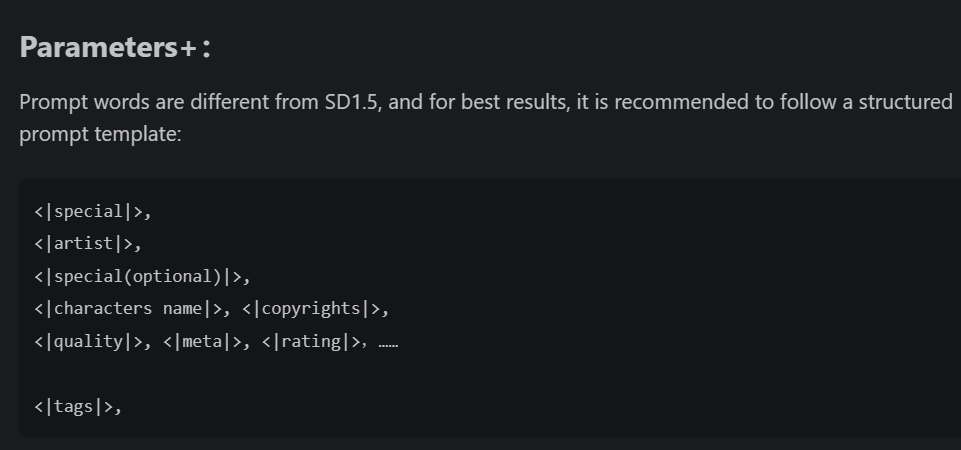

5. 有些东西压根就不是过拟合!
(错误言论)1girl出好图出角色就是过拟合等一系列跟“污染”“过拟合”有关的论点
→污染是现象,但是大多数时候是来自于“欠拟合”或者低品质资料集(该分清楚的标没分清楚)
→实际上很少有练到过拟合的模型,大部分人对过拟合的标准低估了
大部分人看到的可能是灾难性遗忘等,模型本来会的被搞到不会了,过拟合一般来说是出完全一模一样复制出来的图。例如下面这个图就是过拟合的(图片来源:2024-02-24直播錄播[Finetune/LoRA/LyCORIS]_哔哩哔哩_bilibili)
左:生成的图 中:原图 右:原图过VAE

另外差异炼丹过程中,虽然也要炼成出原图,但是模型拟合的目的就是自己,因此不能称为过拟合。
- 1girl出好图
首先1girl出好图也并不能直接说明模型的质量就很烂。
这个说法的出现是因为在很久之前是因为曾有大量模型提示词是几乎没有什么效果并且会乱加不相干的景物细节(写负面提示词都无法去除),生成的图跟在这些模型输入1girl抽卡差不多。而这些模型普遍的特征就是1girl能出比较完善的图,所以有人就通过现象来总结得出结论“1girl出好图的模型十有八九质量都很烂”


